
Tool-calling in production: where LLM agents actually break
A breakdown of failure modes we encountered running tool-calling agents on real business data — retries, hallucinated function names, and context window pressure.
Most failures in LLM-based systems — tool-calling instability, context window pressure, retrieval latency that breaks user experience — are predictable and documented. We publish the engineering analysis of these problems, and work directly with teams that need to solve them.

No press-release rephrasing, no "top 10 AI tools" listicles. Just analysis of real systems.
A breakdown of failure modes we encountered running tool-calling agents on real business data — retries, hallucinated function names, and context window pressure.
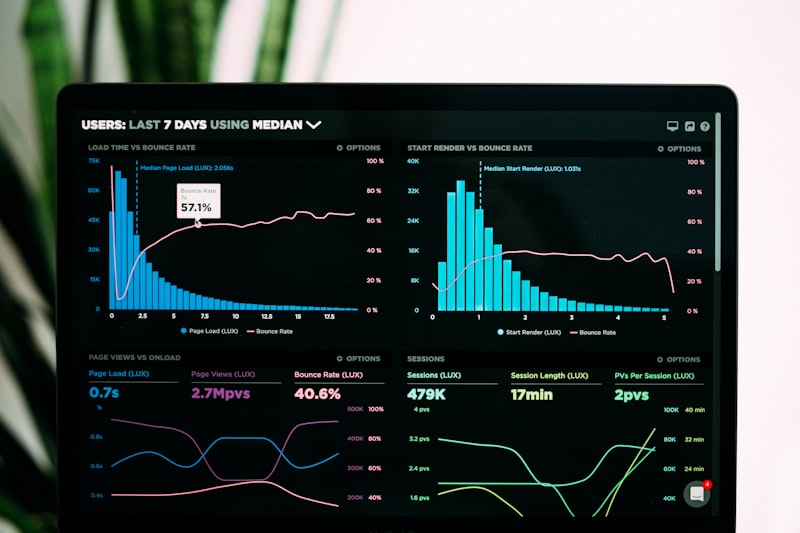
Most automation projects fail before a single API call is made. We walk through the process audit we do before any AI integration engagement.

When does breaking a task into a prompt chain actually outperform one carefully constructed prompt? We tested across five task categories with reproducible results.
We help organizations understand where AI agents fit — and where they don't. Our work is diagnostic and content-driven, not implementation vendor work.
A structured review of your current workflows to identify which processes are actually candidates for AI augmentation — and which aren't.
Learn moreAn independent technical review of an AI-based product or feature — covering architecture, prompt design, failure modes, and risk areas.
Learn moreLong-form technical writing for companies that need credible content — white papers, implementation guides, and deep-dive articles for technical audiences.
Learn more"We came in expecting the audit to confirm what we already planned to build. It didn't. James walked through our document ingestion pipeline and identified two steps we'd assumed were automatable but actually required judgment calls that no current LLM handles reliably at our error tolerance. We deprioritised both. That reallocation probably recovered four to six weeks of engineering time we'd have spent on the wrong thing."

"KP Journal is one of the few places writing about AI agents for people who are actually building them, not evaluating whether to. The article on context window management was the one that hit hardest — specifically the distinction between gradual quality degradation and silent tool-result dropout. We were monitoring for the first and missing the second entirely. We added validation checks on tool-result carryover across turns in our categorization pipeline, and caught two failure patterns that had been running undetected in production for weeks. That's a direct operational outcome from reading an article."

"We commissioned a white paper on agentic document processing for a technical buying audience — architects and senior engineers who would immediately notice if something was abstracted beyond usefulness. The KP Journal team got the architecture section right on the first draft, including the retrieval boundary and audit trail framing. We did one revision round on the compliance language, which they turned around in under 48 hours without losing the technical register. We've used other content vendors for this kind of material."

We built a short diagnostic based on the questions we ask at the start of every audit engagement.
Start the diagnostic