
Tool-calling in production: where LLM agents actually break
A breakdown of failure modes we encountered running tool-calling agents on real business data — retries, hallucinated function names, and context window pressure.
Longer reads on things that are hard to cover in a tweet thread. Reproducible where possible, honest about limitations, no vendor-sponsored angles.
A breakdown of failure modes we encountered running tool-calling agents on real business data — retries, hallucinated function names, and context window pressure.
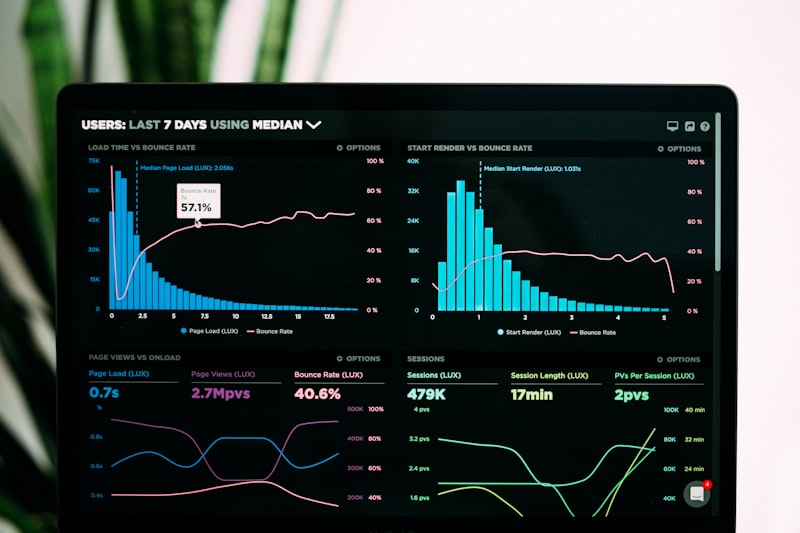
Most automation projects fail before a single API call is made. We walk through the process audit we do before any AI integration engagement.

When does breaking a task into a prompt chain actually outperform one carefully constructed prompt? We tested across five task categories.

How different memory approaches — short-term, episodic, and semantic — affect agent performance across multi-session tasks. A design-level overview with implementation notes.
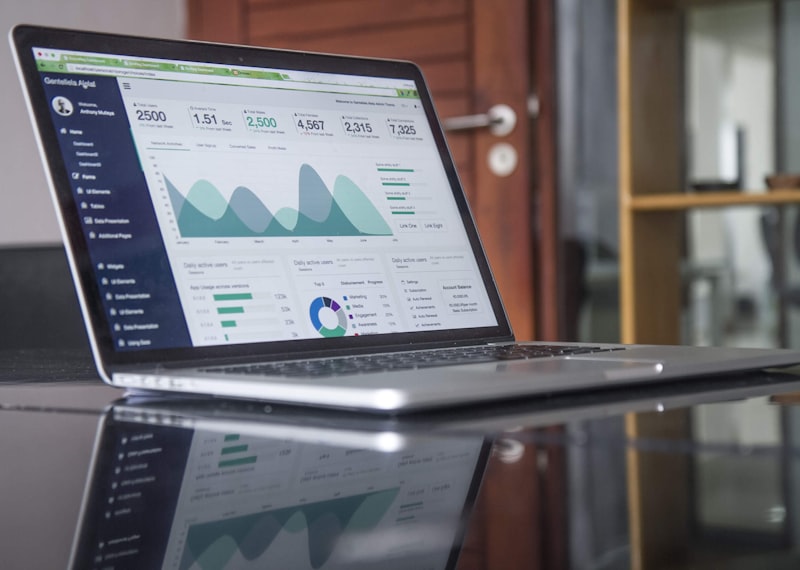
A practical introduction to structured evaluation frameworks for LLM outputs — what metrics actually matter, and how to automate quality checks at scale.